GROUP BY ALL solves a really annoying SQL problem
Does your SQL still copy most of your columns from SELECT after GROUP BY?
Behold: GROUP BY ALL.
- Thanks to
 for supporting this content.
for supporting this content.
The problem¶
A simple example of the problem looks like this. I have a table of page views, one row per view. I want to know how many downloads I had each day, so I write some SQL like this:
See how I have to repeat view_date in the GROUP BY clause? It's required, and it's pretty much the only appropriate simple value. I must add any columns that I'm not aggregating (I used the aggregate function COUNT() here) to the GROUP BY clause for the query to be valid.
Grouping is something we do all the time. It's a minor irritation when there are only a couple of columns to add, but I've seen queries where there are tens, maybe even hundreds of columns that have to be carefully kept synchronised.
A chunkier example from GitHub:
The poor solution¶
I've seen a bad solution around, where you don't need to actually name the columns but can instead use the column's ordinal number. The previous query would look like:
This is a bad idea for readability, and now you have a list of sequential numbers to keep in sync instead. Here's an example I found on GitHub for how silly it can get:
The good solution¶
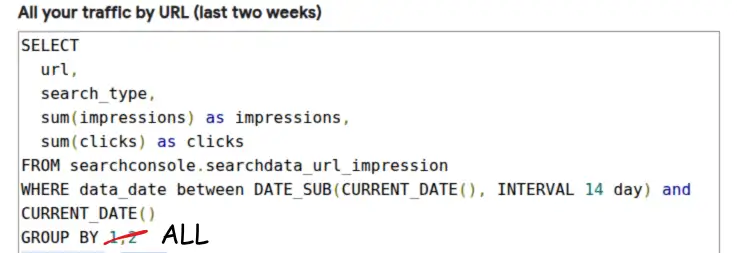
On 23 May 2024, Google made GROUP BY ALL generally available, and I totally missed it. Now, I can just say what I mean  .
.
It doesn't matter if you have one plain select column or 100. GROUP BY ALL infers the list. The full documentation explains the specifics and how the inference works.
Supporting platforms¶
I actually found GROUP BY ALL first on the Databricks platform.
I don't think Trino (and by extension AWS Athena) have GROUP BY ALL.
Feedback
If you want to get in touch with me about the content in this post, you can find me on LinkedIn or raise an issue/start a discussion in the GitHub repo. I'll be happy to credit you for any corrections or additions!
If you liked this, you can find content from other great consultants on the Equal Experts network blogs page