How to get pwned with --extra-index-url
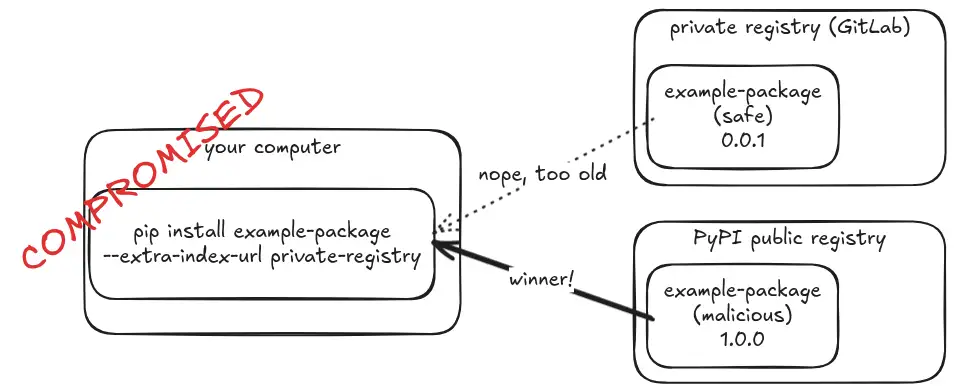
Python's built-in pip package manager is unsafe when used with the --extra-index-url flag (there are other dangerous variants too). An attacker can publish a malicious package with the same name and a higher version to PyPI, and their package will be installed.
This post confirms that the vulnerability (CVE-2018-20225) is still a problem today. Despite the CVSS 7.8 (High) CVSS score, the maintainers have refused to change the behaviour.
I also introduce a test suite and publicly-available test packages that you can use to more easily confirm the safety - or not - of your own setup.